小端序和大端序
写在开头
大家都知道,数据存储在内存中时,由于1字节只有8位,存储的数据范围有限,我们需要将占用多个字节的数据按照特定顺序排列存储。在存储过程中,根据实际使用场景特点,会采用不同的字节序——小端序(Little Endian)和大端序(Big Endian)。
什么是字节序
字节序,又称端序或尾序(Endianness)。在计算机领域中,指电脑内存中或在数字通信链路中,占用多个字节的数据的字节排列顺序。在几乎所有的平台上,多字节对象都被存储为连续的字节序列。
小端序和大端序
首先我们给出这两个字节序的定义:
- 小端序:将高位字节保存在内在存的高地址(低位字节在前)的方式。
- 大端序:将高位字节保存在内存的低地址(高位字节在前)的方式。
以存储0x12345678为例。显然他是一个四字节的数据。大端序的保存数据示意图如下:
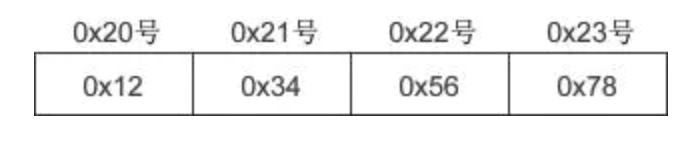
小端序存储结果则如下:
字节序作用
计算机电路先处理低位字节,效率比较高,因为计算都是从低位开始的。所以,计算机的内部处理都是小端字节序。在计算机内部,小端序被广泛应用于现代 CPU 内部存储数据;而在其他场景,比如网络传输和文件存储则使用大端序。
不同CPU保存和解析数据的方式不同(主流的Intel系列CPU为小端序)。现在还有支持两种字节序的处理器(如ARM, 曾经ARM架构的处理器也是小端序,但现在的为支持两种字节序)。
查看计算机的字节序
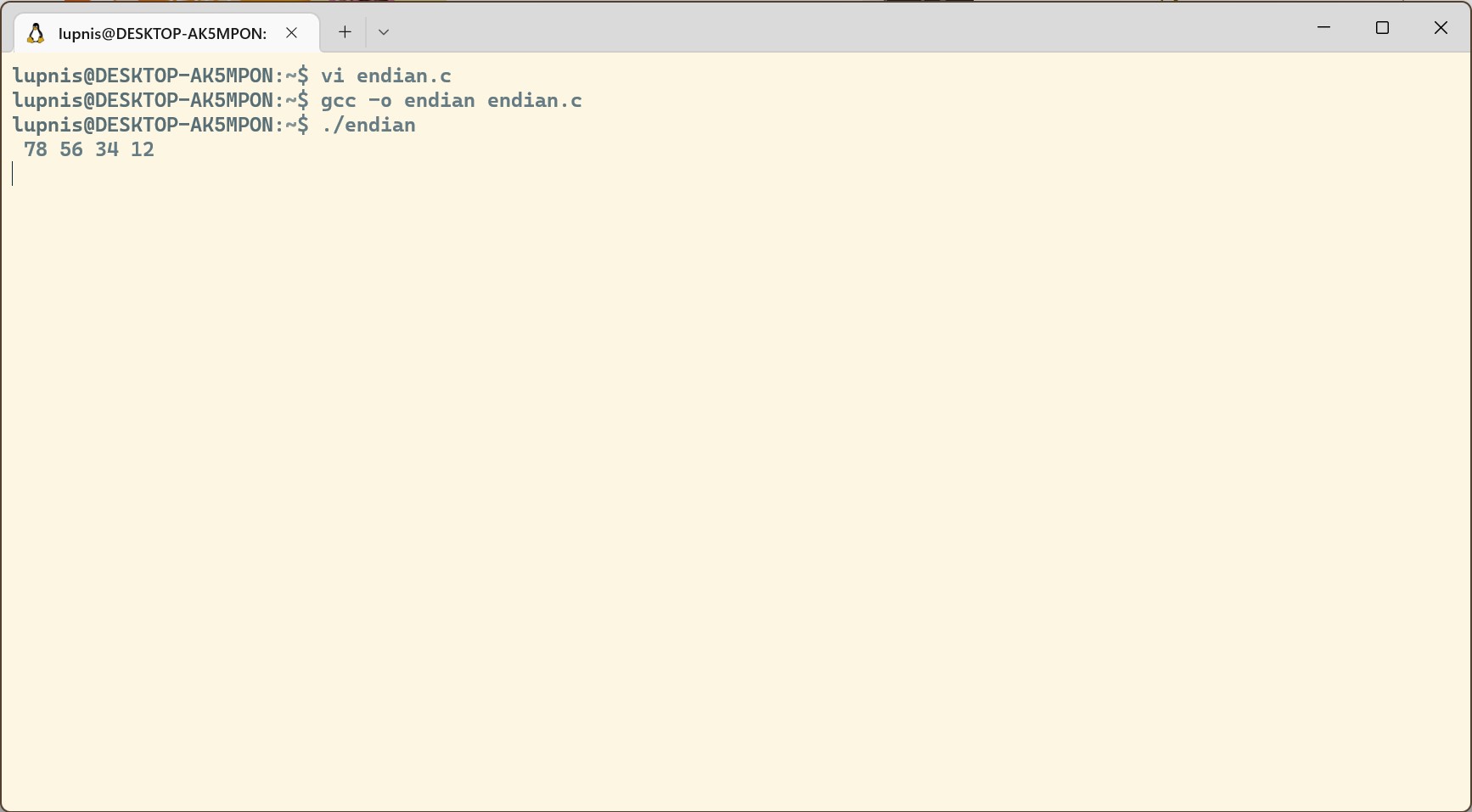
想要查看自己计算机的字节序,只需要将存储的一个多字节数据按内存顺序输出即可。代码如下:
1 |
|
结果如下,测试计算机为小端序。
另外有一种更为方便的检测方法,使用0x00000001,将其转换为占一个字节的字符类型时将会截断原来的存储。由此检测这一字节存储的是1还是0即可确定字节序:
1 | #include <stdio.h> |

大小端转换
大多数时候,编译器会处理字节顺序,但是,在以下情况下,字节顺序会成为一个问题。
它在网络编程中很重要:假设将整数写入小端机器上的文件,然后将此文件传输到大端机器。除非有小端到大端的转换,否则大端机器会倒序读取文件,通信时就会发生数据解析错误。
网络的标准字节序是大端序,也称为网络字节序。在网络上传输数据之前,首先将数据转换为网络字节序。主机A先把数据转换成大端序再进行网络传输,主机B收到数据后先转换为自己的格式再解析。
字节序会搞坏文件吗
既然有这么多字节序,那如果我把一张图片、一首歌或者一个文档转移到不同字节序CPU的电脑上,文件会变得不可读吗?答案是不会的。以1字节为基本单位的文件格式与字节顺序无关。其他文件格式一般会使用一些固定的字节序格式,例如JPEG 文件以大端序格式存储。
哪种字节序更好呢
小端序和大端序的词其实来自Jonathan Swift 的《格列佛游记》。 两群人无法就鸡蛋应该从哪一端打开达成一致——小端还是大端。就像鸡蛋问题一样,没有技术理由选择一个字节排序约定而不是另一个,因此争论退化为关于社会意识问题的争吵。只要选择并始终遵守其中一项约定,该选择就是任意的。

